
Dezentralisierung in der Auswertung von Maschinendaten für Industrieanwendungen
In der Welt der Internet of things (IoT) und Industrie 4.0 sind Lösungen mit Cloud-Technologie nicht mehr wegzudenken. Begriffe wie Software-as-a-Service (SaaS) oder Platform-as-a-Service (PaaS) gehören zum Standard-Glossar in der IoT-Welt. Cloud-Dienste zur Datenanalyse gewinnen im Industrieumfeld zunehmend an Akzeptanz und werden heute schon produktiv in Unternehmen eingesetzt. Doch die zunehmende Menge an generierten Maschinendaten stellt die Auswertung auf der Cloud vor eine Herausforderung und soll langfristig durch Edge- und Fog-Computing entlastet werden. Was Fog und Edge bedeutet, was die Beweggründe für eine Dezentralisierung in der Datenanalyse sind und welche Herausforderung hier bevorsteht soll in diesem Beitrag nähergebracht werden.
Inhalt
Wohin mit den Daten?
Laut der Studie „Data Age 2025“ soll sich die weltweite Datenmenge bis zum Jahr 2025 von 33 ZettaByte auf 175 ZettaByte vervielfachen. Verglichen mit einer handelsüblichen Festplatte mit 2 TeraByte wären hierfür über 87 Milliarden Festplatten notwendig, um diese Datenmenge zu speichern. Dabei gehört der Produktionssektor mit 3584 Exabyte (Stand 2018) mit Abstand zum größten Datenerzeuger aller untersuchten Branchen. Ausgelöst wird diese Datenmenge durch die zunehmende Anzahl an Sensoren, die bereits heute zur Fabrikautomatisierung und -steuerung im 24/7 Betrieb verwendet werden. Darüber hinaus ist der rasante Zuwachs von IoT-Anwendungen wesentlicher Bestandteil der bevorstehenden Datenexplosion.
Warum Dezentralisierung?
Zwar besagt die Studie „Data Age 2025“, dass über 49% aller gesammelten Daten bis zum Jahr 2025 auf Public Clouds gespeichert werden, doch die eigentliche Herausforderung ist dabei das Speichern von Daten mit Echtzeitanforderungen. Sensoren in Fertigungsmaschinen und IoT-Geräten unterliegen in der Regel jener Echtzeitanforderungen zur Umsetzung der gewünschten Regel- und Steuermechanismen. Laut der Studie sollen „Echtzeitdaten“ bis 2025 von 15% auf 30% steigen. Dabei handelt es sich um wahre Datenerzeugungsmotoren. Beispielsweise produziert ein Sensor, der in einem hochdynamischen System mit 1 kHz abgetastet wird, über 345 MegaByte am Tag über 126 GigaByte pro Jahr. Bei einem autonomen Fahrzeug sollen laut Schätzungen sogar über 4 GigaByte an Daten pro Stunde generiert werden.
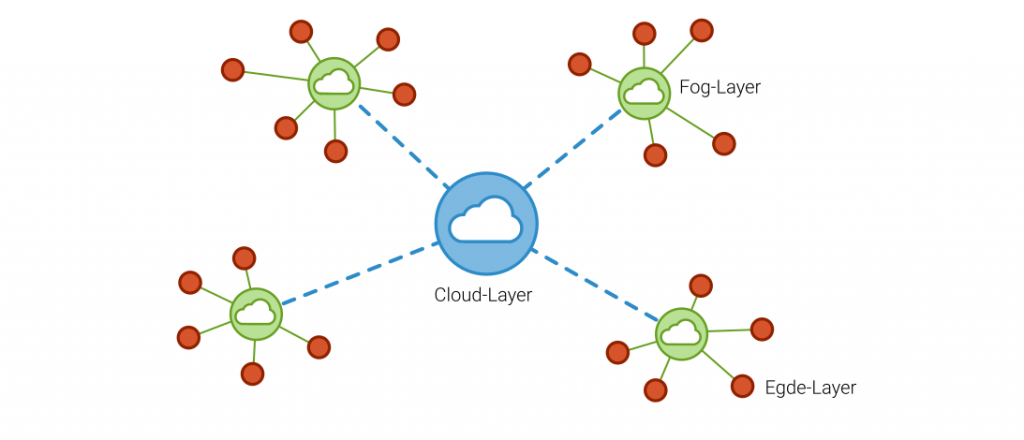
Für Anwendungen mit Latenzkritischen Anforderungen ist mit den heutigen Möglichkeiten der Datenübertragung und -speicherung eine vollständige Datenverarbeitung auf Cloud schwer vorstellbar. Aus diesem Grund entwickelt sich zunehmend der Trend die Vorverarbeitung der Daten direkt an der Maschine oder auf dem Gerät auszuführen, um so die erzeugte Datenmenge zu komprimieren und die benötigte Rechenleistung zu verteilen. Da sich diese Geräte oftmals am Rande des Netzwerks befinden, wird diese Art der Datenverarbeitung als Egde-Computing bezeichnet. Ein Beispiel hierfür ist die Klassierung von Lastkollektiven mit Zählverfahren wie der Rainflow-Klassierung oder der Verbund-Verweildauerzählung. Die Aggregation der Daten kann dann auf der Cloud für Analyse- oder Optimierungsmodelle wie Anomalieerkennung oder Predictive Maintenance verwendet werden.
Klingt doch alles ganz gut, oder?
Nicht ganz. Die Dezentralisierung von Berechnungsmodellen bringt auch viele Nachteile mit sich, die Unternehmen vor eine große Herausforderung stellt oder stellen wird. Eine Datenvorverarbeitung und -komprimierung am Edge entspricht in allen Fällen immer einem Datenverlust, der irreversibel ist. Dies kann sich als besonders nachteilhaft ergeben, wenn die eigentlichen Potenziale in den Daten, beispielsweise durch die Anwendung von Machine Learning Modellen, durch eine zu starke Komprimierung nicht mehr für das Lernverfahren nutzbar sind. Weiterer Nachteil ist die erschwerte Skalierbarkeit der Rechenleistung am Edge, so dass zunehmende Datenmengen oder rechenintensivere Algorithmen nur durch einen Austausch der Rechenkomponenten möglich sind. Zudem fehlt beim Edge-Computing ein herstellerübergreifender Standard und soll von der ECCE (Edge Computing Consortium Europe) erarbeitet werden.
Die Implementierung und Wartung der Geräte und Software kann ohne Standard besonders für Industrieanlagen zu einem hohen Zeit- und Programmieraufwand führen. Nicht nur aus diesen Gründen etabliert sich in der Industriewelt zunehmend die Möglichkeit des Fog-Computing. Das Fog-Computing ist ein Kompromiss aus Cloud und Edge. Es handelt sich hierbei um intelligente Gateways oder lokale Recheneinheiten, die Daten der lokalen Maschinen sammeln und zentral verarbeiten, um diese zur Hauptverarbeitung an die Cloud zu speichern. Das Fog-Computing ist demzufolge das Edge-Computing auf Systemebene und bietet sich besonders für Produktionsanlagen mit herstellerübergreifen Maschinen an.
Ausblick?
Um dem rasanten Datenwachstum in Industrie 4.0 und IoT zu folgen ist eine Dezentralisierung der Datenverarbeitung vorherbestimmt. Laut Umfragen nutzen bereits heute über 58% der befragten Fertigungsunternehmen Edge-Computing Methoden. Der gesamte Edge-Computing Markt soll bis 2023 von 3 Mrd. auf 18 Mrd. Doller wachsen. Die spannende Frage wird sein, wie sich Speicherung und Berechnung auf Cloud, Fog und Edge verteilen oder ob neue Technologien im Bereich Datenübertragung und Speicherung weitere Möglichkeiten bieten. Nichtsdestotrotz werden die Unternehmen vor eine Herausforderung gestellt, die viele Iterationsschritte benötigen wird, um die für sich optimale Lösung zu finden.
So können Sie Ihre Prozesse digitalisieren.

Lesen Sie jetzt mehr in der Case Study.



