
Decentralization in the evaluation of machine data in industrial applications
In the world of Internet of things (IoT) and Industry 4.0, solutions with cloud technology are indispensable. Terms like Software-as-a-Service (SaaS) or Platform-as-a-Service (PaaS) are part of the standard glossary in the world of IoT. Cloud services for data analysis are increasingly gaining acceptance in the industrial environment and are already being used productively in companies today. However, the increasing volume of generated machine data poses a challenge for analysis on the cloud and should be relieved in the long term by edge and fog computing. In this article, we will explain what Fog and Edge mean, what the motives for decentralization in data analysis are and what challenges lie ahead.
Table of Contents
Where to put the data?
According to the study “Data Age 2025“, the worldwide data volume is expected to multiply from 33 ZettaByte to 175 ZettaByte by the year 2025. Compared to a conventional hard disk with 2 TeraByte, this would require more than 87 billion hard disks to store this amount of data. With 3584 exabytes (as of 2018), the production sector is by far the largest data generator of all the industries studied. This data volume is triggered by the increasing number of sensors that are already being used today for factory automation and control in 24/7 operation. In addition, the rapid growth of IoT applications is an essential part of the impending data explosion.
Why decentralization?
Although the study “Data Age 2025” states that over 49% of all collected data will be stored on public clouds by 2025, the real challenge is to store data with real-time requirements. Sensors in production machines and IoT devices are generally subject to those real-time requirements for implementing the desired regulation and control mechanisms. According to the study, “real-time data” should increase from 15% to 30% by 2025. These are true data generation engines. For example, a sensor that is sampled in a highly dynamic system at 1 kHz produces over 345 megabytes per day over 126 gigabytes per year. In an autonomous vehicle, it is estimated that even more than 4 GigaByte of data per hour can be generated (Link).
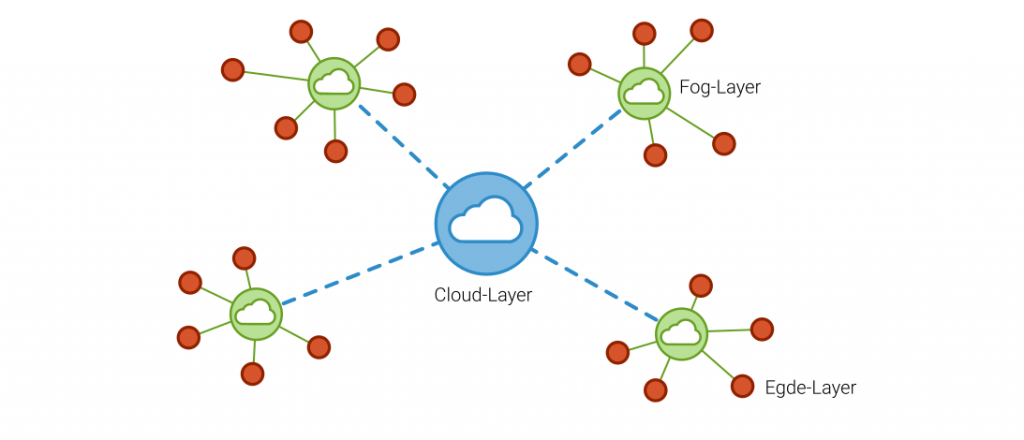
For applications with latency-critical requirements, complete data processing on the cloud is difficult to imagine with today’s possibilities for data transmission and storage. For this reason, there is a growing trend to pre-process data directly at the machine or on the device in order to compress the generated data volume and distribute the required computing power. Since these devices are often located at the edge of the network, this type of data processing is called edge computing. An example of this is the classification of load collectives using counting methods such as Rainflow classification or compound dwell time counting. The aggregation of the data can then be used on the cloud for analysis or optimization models such as anomaly detection or predictive maintenance.
It all sounds pretty good, doesn't it?
Not quite. The decentralization of calculation models also brings with it many disadvantages, which poses or will pose a great challenge to companies. In all cases, data pre-processing and compression at the edge always corresponds to a loss of data that is irreversible. This can be particularly disadvantageous if the actual potential in the data, for example through the use of machine learning models, can no longer be used for the learning process due to excessive compression. A further disadvantage is the difficult scalability of the computing power at the edge, so that increasing amounts of data or more computationally intensive algorithms are only possible by replacing the computing components. In addition, Edge Computing lacks a manufacturer-independent standard and is to be developed by ECCE (Edge Computing Consortium Europe).
Without a standard, the implementation and maintenance of devices and software can lead to a high time and programming effort, especially for industrial plants. It is not only for these reasons that the possibility of fog computing is increasingly establishing itself in the industrial world. Fog Computing is a compromise between Cloud and Edge. These are intelligent gateways or local computing units that collect data from local machines and process it centrally to store it for main processing in the cloud. Fog Computing is therefore system-level edge computing and is particularly suitable for production facilities with multi-vendor machines.
Outlook?
In order to follow the rapid data growth in Industry 4.0 and IoT, a decentralization of data processing is predestined. According to surveys, over 58% of the manufacturing companies surveyed already use edge computing methods. The entire edge computing market is expected to grow from 3 billion to 18 billion dollars by 2023. The exciting question will be how storage and computing will be distributed among Cloud, Fog and Edge or whether new technologies in the area of data transmission and storage will offer further opportunities. Nevertheless, companies will be faced with a challenge that will require many iteration steps to find the best solution for them.
How can you digitize your workflow?
sentin GmbH develops and distributes inspection software based on artificial intelligence for industrial use. Take your quality control to the next level – learn more about the sentin EXPLORER in our brochure.

Learn more in our case study.



